redis源码学习-dict篇
0 条评论redis源码学习-dict篇
dict介绍
redis中的dict(字典)实际上是一个安全的实现了rehash的多态哈希桶,是一个性能较高的数据结构,用来保存键值对,类似其他高级语言的map。
dict分析
dict作为一个基于hash提高性能的kv结构,通过开链法/拉链法的方式解决hash冲突。但也因此会存在桶倾斜的问题。优化链表过长的方式有很多,比如java中concurrenthashmap在链表长度达到一定值时将单链表重构成红黑树等。redis解决hash冲突的方式为rehash,通过在声明dict时直接分配**ht_table[2],其中一个ht_table只有在rehash的时候起效,同时辅助设置rehashidx等字段标示是否在rehash状态,实现了安全的rehash。
dict数据结构定义有三个,这里依次分析(6中将typedef struct dictht优化掉了)
dictEntry:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* Next entry in the same hash bucket. */
void *metadata[]; /* An arbitrary number of bytes (starting at a
* pointer-aligned address) of size as returned
* by dictType's dictEntryMetadataBytes(). */
} dictEntry;
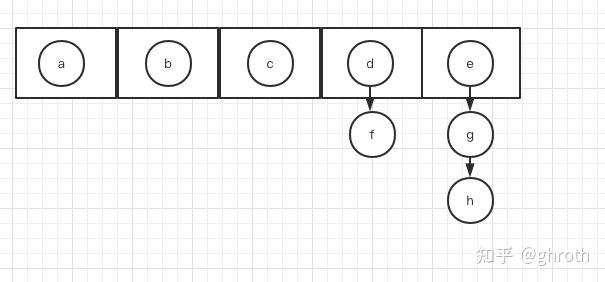
dictEntry为具体的dict节点结构了,可以看到其中有next指针,指向另一个dictEntry。借助注释中的/* Next entry in the same hash bucket. */可以很好的理解了文章最开始说的开链法/拉链法。哈希桶的结构如下:
先讲几个概念
哈希散列:
若结构中存在和关键字K相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数(Hash function),按这个事先建立的表为散列表(来自百度)
翻译一下的话,假如有k长度的数组,n个数字,通过一定的规则f将n个数字尽量均匀的放到k个数组中,而在查找某个数字在哪里时,通过规则f直接就能查到在哪里了,无需循环遍历整个数组。其中规则f有很多种方式,有时因地制宜。常见的就是n个数字,k长度的数组,每个数字对k进行取余。又比如有些手机号,那么就取最后四位,身份证号取*****进行取余等等等等。
哈希冲突:
还是以对k取余为例,当两个数字对k取余得到了相同的结果时,就产生了冲突。,举个简单例子,有0 1 2 3 4 5共六个数,有[5]的数组,那么在0-4时会变成
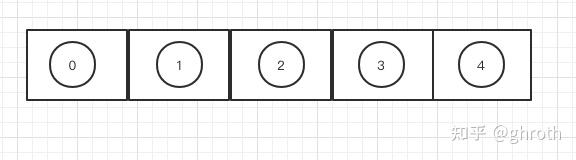
一个数一个坑位。当开始插入5时,发现0已经占了,那么哈希桶的方式怎么办呢?开个链表。0这里不止记录自己,还记录我有next,next那个数是5,如图
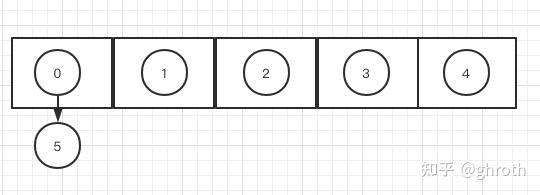
所以说,dictEntry中的next就是做这个的。
dictType:
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(dict *d, const void *key);
void *(*valDup)(dict *d, const void *obj);
int (*keyCompare)(dict *d, const void *key1, const void *key2);
void (*keyDestructor)(dict *d, void *key);
void (*valDestructor)(dict *d, void *obj);
int (*expandAllowed)(size_t moreMem, double usedRatio);
/* Allow a dictEntry to carry extra caller-defined metadata. The
* extra memory is initialized to 0 when a dictEntry is allocated. */
size_t (*dictEntryMetadataBytes)(dict *d);
} dictType;
看注释的话,这里允许dictEntry携带额外的调用者定义的元数据,而dict自身就依赖此实现多态。这里的方法稍后分析。
dict:
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
};
dict最后向外暴露的就是这个了。
可以看到,定义了type,数据为ht_table[2](两个用来做rehash)。ht_used[2]对应的是ht_table[2]中的所用length。rehashidx则为保证安全rehash的标识符,rehashing not in progress if rehashidx == -1 。pauserehash为6后新加入的特性,为保证效率新增rehash的paused的操作。exponent这里为2的多少次方,这个特性也是比较常见的,比如centos的网络中,connection timeout的retry策略就是,第一次1s超时,第二次2s超时,第三次4s超时++++(所以一般机器层面的连接超时大多都是1s,3s,7s,15s++++)
dict方法分析:
create:
/* Reset a hash table already initialized with ht_init().
* NOTE: This function should only be called by ht_destroy(). */
static void _dictReset(dict *d, int htidx)
{
d->ht_table[htidx] = NULL;
d->ht_size_exp[htidx] = -1;
d->ht_used[htidx] = 0;
}
/* Create a new hash table */
dict *dictCreate(dictType *type)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type);
return d;
}
/* Initialize the hash table */
int _dictInit(dict *d, dictType *type)
{
_dictReset(d, 0);
_dictReset(d, 1);
d->type = type;
d->rehashidx = -1;
d->pauserehash = 0;
return DICT_OK;
}
分配堆内存仍然使用的zmalloc.c中的zmalloc。初始化时需要指定dictType,其余的给予默认值,两个dictEntry和所标识的ht_size_exp,ht_used完全一致。
insert:
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
//调用dictAddRaw后,如果key已经冲突,则返回1
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
//key没有被占用,正常add进去的话,则返回0
return DICT_OK;
}
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
int htidx;
//判断这里是到达了rehashing的条件,如果需要的话则进行rehash,rehash为while循环,需要等得rehash完之后才能进行add
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
//如果key存在的话,直接返回
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
//查看是否rehash,假如在rehash的话,那么就只在ht_table[1]进行插入,而在select时,则就需要同时在ht_table[0]和ht_table[1]上都查找了
//这么做对于查找来说增加了一定的时间,但是对于内存上有节省,算是以空间换时间的一种形式
htidx = dictIsRehashing(d) ? 1 : 0;
size_t metasize = dictMetadataSize(d);
entry = zmalloc(sizeof(*entry) + metasize);
//调用c库函数,假如value值不为空的话,使用memset赋值给此函数最开始声明的entry
if (metasize > 0) {
memset(dictMetadata(entry), 0, metasize);
}
entry->next = d->ht_table[htidx][index];
d->ht_table[htidx][index] = entry;
d->ht_used[htidx]++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
reset:
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, *existing, auxentry;
/* Try to add the element. If the key
* does not exists dictAdd will succeed. */
//首先尝试调用插入,假如能插入则说明本身没有,直接返回即可
entry = dictAddRaw(d,key,&existing);
if (entry) {
dictSetVal(d, entry, val);
return 1;
}
/* Set the new value and free the old one. Note that it is important
* to do that in this order, as the value may just be exactly the same
* as the previous one. In this context, think to reference counting,
* you want to increment (set), and then decrement (free), and not the
* reverse. */
//如果已有数据,需要替换value,那么就先记录原值的内存地址,然后重新赋值,之后根据记录的地址进行free操作
auxentry = *existing;
dictSetVal(d, existing, val);
dictFreeVal(d, &auxentry);
return 0;
}
delete:
int dictDelete(dict *ht, const void *key) {
return dictGenericDelete(ht,key,0) ? DICT_OK : DICT_ERR;
}
/* Search and remove an element. This is a helper function for
* dictDelete() and dictUnlink(), please check the top comment
* of those functions. */
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
/* dict is empty */
if (dictSize(d) == 0) return NULL;
//判断这里是到达了rehashing的条件,如果需要的话则进行rehash,rehash为while循环,需要等得rehash完之后才能进行add
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
//计算hash值
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
he = d->ht_table[table][idx];
prevHe = NULL;
while(he) {
//假如在桶内循环找到了这个key,那么将他的上一个next指针指向他的下一个,避免丢失入口,然后删除此entry
if (key==he->key || dictCompareKeys(d, key, he->key)) {
/* Unlink the element from the list */
if (prevHe)
prevHe->next = he->next;
else
d->ht_table[table][idx] = he->next;
if (!nofree) {
dictFreeUnlinkedEntry(d, he);
}
d->ht_used[table]--;
return he;
}
prevHe = he;
he = he->next;
}//如果没有在rehash的话,继续delete,如果在rehash的过程中delete的话,那么不会执行删除
if (!dictIsRehashing(d)) break;
}
return NULL; /* not found */
}
search:
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
he = d->ht_table[table][idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
这里和delete的逻辑几乎完全相同,只不过是delet在定位到key后做链表重定向,而find操作就简单一些了,直接返回。所以这里就只放源码不加注释了。
rehash:
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht_used[0] != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(DICTHT_SIZE(d->ht_size_exp[0]) > (unsigned long)d->rehashidx);
while(d->ht_table[0][d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht_table[0][d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & DICTHT_SIZE_MASK(d->ht_size_exp[1]);
de->next = d->ht_table[1][h];
d->ht_table[1][h] = de;
d->ht_used[0]--;
d->ht_used[1]++;
de = nextde;
}
d->ht_table[0][d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht_used[0] == 0) {
zfree(d->ht_table[0]);
/* Copy the new ht onto the old one */
d->ht_table[0] = d->ht_table[1];
d->ht_used[0] = d->ht_used[1];
d->ht_size_exp[0] = d->ht_size_exp[1];
_dictReset(d, 1);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
对于代码上对外交互较多,需要完整的理解,这里就用文字解释了。
redis的rehash为渐进式的,redis本身不能够保证redis的dict数据量极端值,假如在数据量极大的情况下,rehash所有的kv,那么redis在rehash的过程中将会导致大量的阻塞,导致业务故障,因此redis为保证效率的同时,每次只对dict的**一个桶做rehash。**也因此引入了rehashidx字段,表示现在rehash到了哪个桶上,当到了最后一个桶,那么就rehash完毕,rehashidx变为-1。但也因此,rehash的过程就有可能持续很长时间了。在dict完成全部rehash之前,会有增删改查四个操作。由于不确定此key是否已经被rehash,那么查找时需要对两个ht_table同时查找。插入时,由于redis已经判断现在出现了桶倾斜,因此只插入到ht_table[1]中,而删除与修改和查找一致,都需要从两个ht_table找。rehash的渐进式触发条件为每一次的增删查。在上述解释中可以看到,redis将一个完整的rehash按桶渐进,分解成每一步增删查操作,将一次大的阻塞平摊到所有的操作中,达到高性能优化的目的。
触发rehash的条件:
* the number of elements and the buckets > dict_force_resize_ratio. */
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5;
- 服务器当前没有在执行BG-SAVE或BG-AOF命令且哈希表的负载因子大于等于1时进行扩展操作
- 服务器正在执行BG-SAVE或BG-AOF命令且哈希表的负载因子大于等于5时进行扩展操作
rehash缩容:
/* This is the initial size of every hash table */
#define DICT_HT_INITIAL_SIZE 4
/* Hash table parameters */
#define HASHTABLE_MIN_FILL 10 /* Minimal hash table fill 10% */
#define HASHTABLE_MAX_LOAD_FACTOR 1.618 /* Maximum hash table load factor. */
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
如上方法部分来自zset,以zset为例,
当哈希表的大小大于 4,且字典的填充率低于 10时进行缩容

