redis源码学习-db篇
0 条评论redis源码学习-db篇
redis为缓存kv数据库,而数据库的概念体现在db结构中。redis中的db默认分为16个,从0-15开始,默认使用0号数据库,每个数据库互不干涉,但仍为单线程结构。在cluster模式中,所有节点全部使用db0。
db与上层容器和底层数据结构调用关系
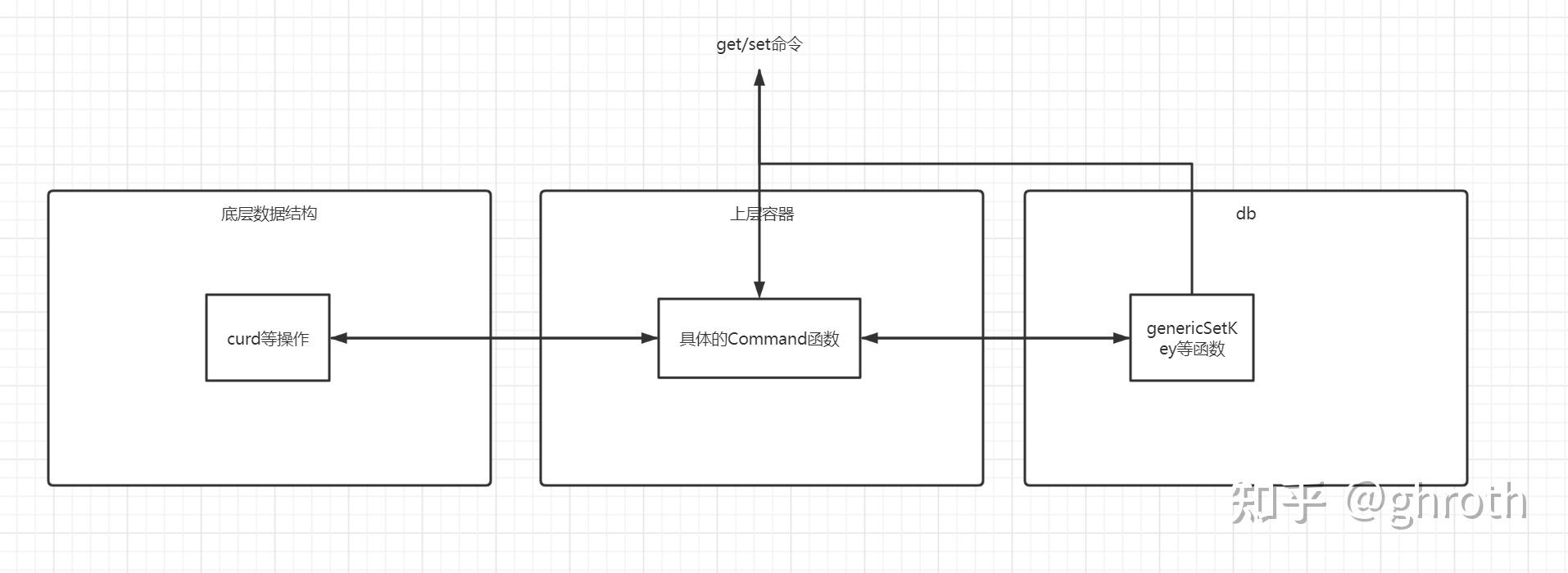
底层数据结构与上层容器合集在
其中比较重要的是dict底层数据结构,为db结构的核心支撑
虽然客户端命令的入口都在上层容器自身的command函数中,但是每个command函数在开始时都会从db中找寻对应的key结构,不同的上层容器结构共用相同的db的key,例如

一个key首先被t_string容器使用,再之后使用t_zset存储相同的key时就会报错。
总之,redis实例中,所有存储的key-value,key全部会写入到相对应db中dict结构上,不区分类型,只存储key与value对应地址,类型判断由上层容器负责。也因此,上层容器的增删改都会额外调用db结构进行相对应的更新,这也是redis核心get/set无法多线程的原因之一。
db源码分析
db结构
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
其中,*dict为核心存储,expires用来处理键的过期行为,blocking_keys使用较少,redis整个只有blpop等会造成主动阻塞。ready_keys与blocking_keys搭配使用,当下次push时,检查blocking_keys当中是否存在对应的key,之后采取相对应的操作。watched_keys负责实现watch功能,但watch对redis性能影响极大,线上环境禁止使用。
查找key
/* Low level key lookup API, not actually called directly from commands
* implementations that should instead rely on lookupKeyRead(),
* lookupKeyWrite() and lookupKeyReadWithFlags(). */
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
/* Update the access time for the ageing algorithm.
* Don't do it if we have a saving child, as this will trigger
* a copy on write madness. */
//更新lru时间,防止出现写拷贝的bug
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
val->lru = LRU_CLOCK();
}
}
return val;
} else {
return NULL;
}
}
/* Lookup a key for read operations, or return NULL if the key is not found
* in the specified DB.
*
* As a side effect of calling this function:
* 1. A key gets expired if it reached it's TTL.
* 2. The key last access time is updated.
* 3. The global keys hits/misses stats are updated (reported in INFO).
* 4. If keyspace notifications are enabled, a "keymiss" notification is fired.
*
* This API should not be used when we write to the key after obtaining
* the object linked to the key, but only for read only operations.
*
* Flags change the behavior of this command:
*
* LOOKUP_NONE (or zero): no special flags are passed.
* LOOKUP_NOTOUCH: don't alter the last access time of the key.
*
* Note: this function also returns NULL if the key is logically expired
* but still existing, in case this is a slave, since this API is called only
* for read operations. Even if the key expiry is master-driven, we can
* correctly report a key is expired on slaves even if the master is lagging
* expiring our key via DELs in the replication link. */
robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) {
robj *val;
//进行过期检查
if (expireIfNeeded(db,key) == 1) {
/* If we are in the context of a master, expireIfNeeded() returns 1
* when the key is no longer valid, so we can return NULL ASAP. */
if (server.masterhost == NULL)
goto keymiss;
/* However if we are in the context of a slave, expireIfNeeded() will
* not really try to expire the key, it only returns information
* about the "logical" status of the key: key expiring is up to the
* master in order to have a consistent view of master's data set.
*
* However, if the command caller is not the master, and as additional
* safety measure, the command invoked is a read-only command, we can
* safely return NULL here, and provide a more consistent behavior
* to clients accessing expired values in a read-only fashion, that
* will say the key as non existing.
*
* Notably this covers GETs when slaves are used to scale reads. */
if (server.current_client &&
server.current_client != server.master &&
server.current_client->cmd &&
server.current_client->cmd->flags & CMD_READONLY)
{
goto keymiss;
}
}
val = lookupKey(db,key,flags);
//命中/未命中统计,每个db共享一份数据
if (val == NULL)
goto keymiss;
server.stat_keyspace_hits++;
return val;
keymiss:
if (!(flags & LOOKUP_NONOTIFY)) {
notifyKeyspaceEvent(NOTIFY_KEY_MISS, "keymiss", key, db->id);
}
server.stat_keyspace_misses++;
return NULL;
}
可以看到,查找key最终只是从dict结构find,得益于dict的渐进式rehash,redis在最终上的hash上不会发生太大倾斜,但渐进式rehash的劣势也在于,当大量的key存在时,一次渐进式rehash需要调整的节点将会过多,业务上也需注意包装key,防范hash碰撞攻击 。
新增key
/* Add the key to the DB. It's up to the caller to increment the reference
* counter of the value if needed.
*
* The program is aborted if the key already exists. */
void dbAdd(redisDb *db, robj *key, robj *val) {
sds copy = sdsdup(key->ptr);
dictEntry *de = dictAddRaw(db->dict, copy, NULL);
serverAssertWithInfo(NULL, key, de != NULL);
dictSetVal(db->dict, de, val);
//每次add需要判断是否blob住
signalKeyAsReady(db, key, val->type);
//cluster模式时,需要记录slot信息
if (server.cluster_enabled) slotToKeyAddEntry(de);
}
清空db
/* FLUSHALL [ASYNC]
*
* Flushes the whole server data set. */
void flushallCommand(client *c) {
int flags;
if (getFlushCommandFlags(c,&flags) == C_ERR) return;
flushAllDataAndResetRDB(flags);
addReply(c,shared.ok);
}
/* Flushes the whole server data set. */
void flushAllDataAndResetRDB(int flags) {
server.dirty += emptyDb(-1,flags,NULL);
if (server.child_type == CHILD_TYPE_RDB) killRDBChild();
if (server.saveparamslen > 0) {
/* Normally rdbSave() will reset dirty, but we don't want this here
* as otherwise FLUSHALL will not be replicated nor put into the AOF. */
int saved_dirty = server.dirty;
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
rdbSave(server.rdb_filename,rsiptr);
server.dirty = saved_dirty;
}
/* Without that extra dirty++, when db was already empty, FLUSHALL will
* not be replicated nor put into the AOF. */
server.dirty++;
#if defined(USE_JEMALLOC)
/* jemalloc 5 doesn't release pages back to the OS when there's no traffic.
* for large databases, flushdb blocks for long anyway, so a bit more won't
* harm and this way the flush and purge will be synchroneus. */
if (!(flags & EMPTYDB_ASYNC))
jemalloc_purge();
#endif
}
long long emptyDb(int dbnum, int flags, void(callback)(dict*)) {
int async = (flags & EMPTYDB_ASYNC);
RedisModuleFlushInfoV1 fi = {REDISMODULE_FLUSHINFO_VERSION,!async,dbnum};
long long removed = 0;
if (dbnum < -1 || dbnum >= server.dbnum) {
errno = EINVAL;
return -1;
}
/* Fire the flushdb modules event. */
moduleFireServerEvent(REDISMODULE_EVENT_FLUSHDB,
REDISMODULE_SUBEVENT_FLUSHDB_START,
&fi);
/* Make sure the WATCHed keys are affected by the FLUSH* commands.
* Note that we need to call the function while the keys are still
* there. */
signalFlushedDb(dbnum, async);
/* Empty redis database structure. */
removed = emptyDbStructure(server.db, dbnum, async, callback);
/* Flush slots to keys map if enable cluster, we can flush entire
* slots to keys map whatever dbnum because only support one DB
* in cluster mode. */
if (server.cluster_enabled) slotToKeyFlush();
if (dbnum == -1) flushSlaveKeysWithExpireList();
/* Also fire the end event. Note that this event will fire almost
* immediately after the start event if the flush is asynchronous. */
moduleFireServerEvent(REDISMODULE_EVENT_FLUSHDB,
REDISMODULE_SUBEVENT_FLUSHDB_END,
&fi);
return removed;
}
/* Set CLIENT_DIRTY_CAS to all clients of DB when DB is dirty.
* It may happen in the following situations:
* FLUSHDB, FLUSHALL, SWAPDB
*
* replaced_with: for SWAPDB, the WATCH should be invalidated if
* the key exists in either of them, and skipped only if it
* doesn't exist in both. */
void touchAllWatchedKeysInDb(redisDb *emptied, redisDb *replaced_with) {
listIter li;
listNode *ln;
dictEntry *de;
if (dictSize(emptied->watched_keys) == 0) return;
dictIterator *di = dictGetSafeIterator(emptied->watched_keys);
while((de = dictNext(di)) != NULL) {
robj *key = dictGetKey(de);
if (dictFind(emptied->dict, key->ptr) ||
(replaced_with && dictFind(replaced_with->dict, key->ptr)))
{
list *clients = dictGetVal(de);
if (!clients) continue;
listRewind(clients,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags |= CLIENT_DIRTY_CAS;
}
}
}
dictReleaseIterator(di);
}
db总结
db结构整体不复杂,熟悉底层数据结构与上层容器后很容易理解,在cluster模式中只能够使用db0,业务平常的使用时也是只使用db0。db名称无法更改,也无法动态扩容db。从源码上看支持动态扩容db与支持db重命名并不复杂,麻烦点在于各个业务驱动的兼容。使用redis时,有条件的话还是使用多个db,会使每个db在每次rehash时稍快一些。

