redis源码学习-listpack篇
0 条评论redis源码学习-listpack篇
listpack介绍
listpack(紧凑列表)可以理解为一个替代版本的ziplist,ziplist具体内容可以在
中进行回顾。
由于ziplist中有着致命的缺陷-连锁更新,在极端条件下会有着极差的性能,导致整个redis响应变慢。因此在redis5中引入了新的数据结构listpack,作为ziplist的替代版。listpack在6以后已经作为t_hash的基础底层结构。
listpack分析
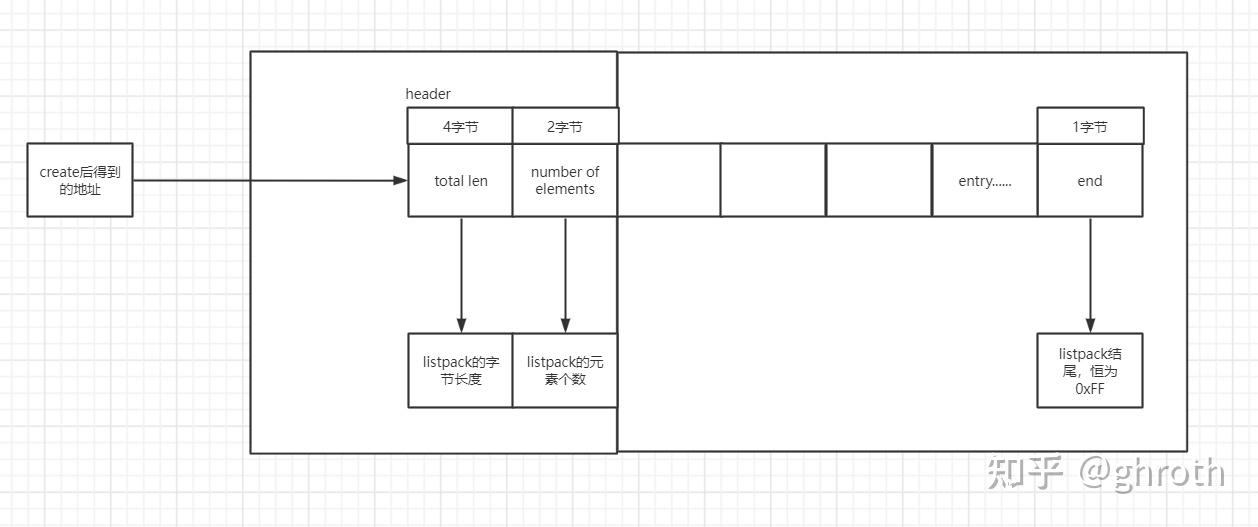
listpack虽然说是ziplist的改进版,但是整体思路与ziplist无太大差别,listpack的结构图如下
单独看这个图会感觉比较眼熟,这里再放下ziplist的结构图示:
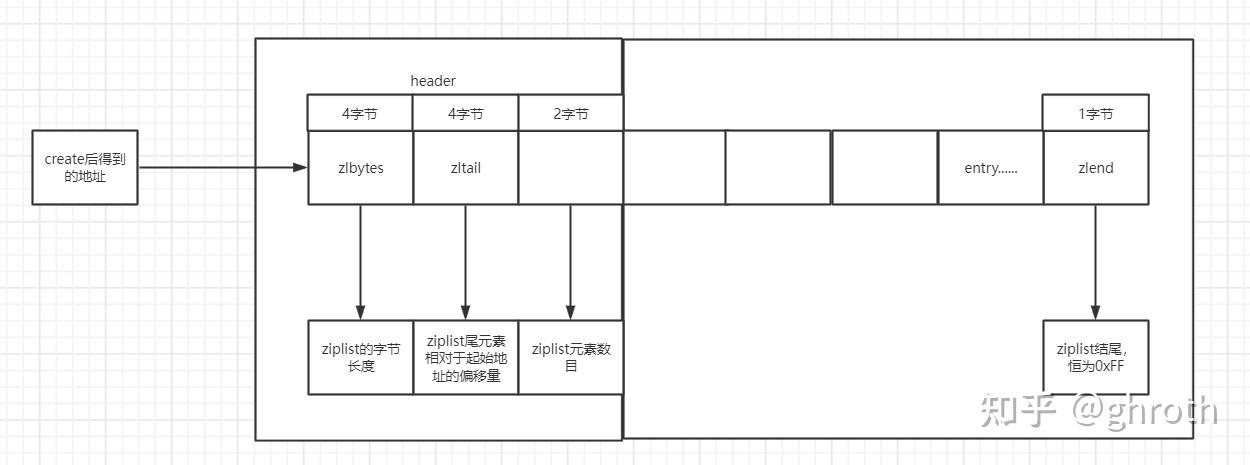
会发现整体上看,listpack少了一些。其实相比较ziplist,listpack中的优化在于entry中。
listpackEntry:
/* Each entry in the listpack is either a string or an integer. */
typedef struct {
/* When string is used, it is provided with the length (slen). */
unsigned char *sval;
uint32_t slen;
/* When integer is used, 'sval' is NULL, and lval holds the value. */
long long lval;
} listpackEntry;
listpackEntry中的改进 :
不同于ziplist,listpackEntry中的len记录的是**当前entry的长度,而非上一个entry的长度。**listpackEntry中可存储的为字符串或整型。
- 当存储的为字符串,那么lsentry的sval不为空,slen记录大小。
- 当存储的为整形,那么lval记录整型,sval字段为空
listpackNew:
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
结合宏
#define LP_HDR_SIZE 6 /* 32 bit total len + 16 bit number of elements. */
#define LP_EOF 0xFF
可以看出,hdr中长度为6字节,申请堆内存时共申请LP_HDR_SIZE +1,4字节用来记录totalLen,2字节用来记录元素的个数,+1的一个字节用来标识end,end也恒为0xFF
由于整体上看,listpack与ziplist结构差别不大,本篇只针对listpack中如何避免连锁更新进行源码分析。
lpInsert:
unsigned char *lpInsert(unsigned char *lp, unsigned char *elestr, unsigned char *eleint,
uint32_t size, unsigned char *p, int where, unsigned char **newp)
{
//#define LP_MAX_INT_ENCODING_LEN 9
unsigned char intenc[LP_MAX_INT_ENCODING_LEN];
//#define LP_MAX_BACKLEN_SIZE 5
unsigned char backlen[LP_MAX_BACKLEN_SIZE];
uint64_t enclen; /* The length of the encoded element. */
int delete = (elestr == NULL && eleint == NULL);
/* when deletion, it is conceptually replacing the element with a
* zero-length element. So whatever we get passed as 'where', set
* it to LP_REPLACE. */
//在lp中,删除并非为真正的删除,而是用 zero-length element替换掉需删除的entry,在这里根据delete字段判断,假如不传elestr和eleint,那么就是替换操作。
if (delete) where = LP_REPLACE;
/* If we need to insert after the current element, we just jump to the
* next element (that could be the EOF one) and handle the case of
* inserting before. So the function will actually deal with just two
* cases: LP_BEFORE and LP_REPLACE. */
//假如当前操作为LP_AFTER,那么处理一下,将LP_AFTER操作变为LP_BEFORE,在接下来的操作中就无需开分支处理了。
if (where == LP_AFTER) {
p = lpSkip(p);
where = LP_BEFORE;
ASSERT_INTEGRITY(lp, p);
}
/* Store the offset of the element 'p', so that we can obtain its
* address again after a reallocation. */
//记录元素记录p之前的长度。由于lp的设置,在插入或删除后此长度不受影响
unsigned long poff = p-lp;
int enctype;
//插入str的具体操作
if (elestr) {
/* Calling lpEncodeGetType() results into the encoded version of the
* element to be stored into 'intenc' in case it is representable as
* an integer: in that case, the function returns LP_ENCODING_INT.
* Otherwise if LP_ENCODING_STR is returned, we'll have to call
* lpEncodeString() to actually write the encoded string on place later.
*
* Whatever the returned encoding is, 'enclen' is populated with the
* length of the encoded element. */
//获取ele的实际encoding
enctype = lpEncodeGetType(elestr,size,intenc,&enclen);
if (enctype == LP_ENCODING_INT) eleint = intenc;
} else if (eleint) {
enctype = LP_ENCODING_INT;
enclen = size; /* 'size' is the length of the encoded integer element. */
} else {
enctype = -1;
enclen = 0;
}
/* We need to also encode the backward-parsable length of the element
* and append it to the end: this allows to traverse the listpack from
* the end to the start. */
//通过上边提前取得的enclen,解码length的长度,如果为删除操作则无需
unsigned long backlen_size = (!delete) ? lpEncodeBacklen(backlen,enclen) : 0;
uint64_t old_listpack_bytes = lpGetTotalBytes(lp);
uint32_t replaced_len = 0;
//这里是处理删除操作的具体方法
if (where == LP_REPLACE) {
replaced_len = lpCurrentEncodedSizeUnsafe(p);
replaced_len += lpEncodeBacklen(NULL,replaced_len);
ASSERT_INTEGRITY_LEN(lp, p, replaced_len);
}
//在这里就可以获取到现在的lp大小了
uint64_t new_listpack_bytes = old_listpack_bytes + enclen + backlen_size
- replaced_len;
//越界判断
if (new_listpack_bytes > UINT32_MAX) return NULL;
/* We now need to reallocate in order to make space or shrink the
* allocation (in case 'when' value is LP_REPLACE and the new element is
* smaller). However we do that before memmoving the memory to
* make room for the new element if the final allocation will get
* larger, or we do it after if the final allocation will get smaller. */
//poff为之前获取到的p之前的位置,这里的dst则定位到该在哪个地方中进行插入或删除了
unsigned char *dst = lp + poff; /* May be updated after reallocation. */
/* Realloc before: we need more room. */
if (new_listpack_bytes > old_listpack_bytes &&
new_listpack_bytes > lp_malloc_size(lp)) {
if ((lp = lp_realloc(lp,new_listpack_bytes)) == NULL) return NULL;
dst = lp + poff;
}
/* Setup the listpack relocating the elements to make the exact room
* we need to store the new one. */
//在之前针对LP_AFTER做的设置后,本函数中只有LP_BEFORE与LP_REPLACE,算是比较好的优化了四类情况
if (where == LP_BEFORE) {
memmove(dst+enclen+backlen_size,dst,old_listpack_bytes-poff);
} else { /* LP_REPLACE. */
long lendiff = (enclen+backlen_size)-replaced_len;
//可以仔细看下传入参数,发现删除就是把当前元素len置空
memmove(dst+replaced_len+lendiff,
dst+replaced_len,
old_listpack_bytes-poff-replaced_len);
}
/* Realloc after: we need to free space. */
if (new_listpack_bytes < old_listpack_bytes) {
if ((lp = lp_realloc(lp,new_listpack_bytes)) == NULL) return NULL;
dst = lp + poff;
}
/* Store the entry. */
if (newp) {
*newp = dst;
/* In case of deletion, set 'newp' to NULL if the next element is
* the EOF element. */
if (delete && dst[0] == LP_EOF) *newp = NULL;
}
if (!delete) {
if (enctype == LP_ENCODING_INT) {
memcpy(dst,eleint,enclen);
} else {
lpEncodeString(dst,elestr,size);
}
dst += enclen;
memcpy(dst,backlen,backlen_size);
dst += backlen_size;
}
//更新hdr
/* Update header. */
if (where != LP_REPLACE || delete) {
uint32_t num_elements = lpGetNumElements(lp);
if (num_elements != LP_HDR_NUMELE_UNKNOWN) {
if (!delete)
lpSetNumElements(lp,num_elements+1);
else
lpSetNumElements(lp,num_elements-1);
}
}
lpSetTotalBytes(lp,new_listpack_bytes);
#if 0
/* This code path is normally disabled: what it does is to force listpack
* to return *always* a new pointer after performing some modification to
* the listpack, even if the previous allocation was enough. This is useful
* in order to spot bugs in code using listpacks: by doing so we can find
* if the caller forgets to set the new pointer where the listpack reference
* is stored, after an update. */
unsigned char *oldlp = lp;
lp = lp_malloc(new_listpack_bytes);
memcpy(lp,oldlp,new_listpack_bytes);
if (newp) {
unsigned long offset = (*newp)-oldlp;
*newp = lp + offset;
}
/* Make sure the old allocation contains garbage. */
memset(oldlp,'A',new_listpack_bytes);
lp_free(oldlp);
#endif
return lp;
}
可以看出,listpack中的增删改统一在一段代码中。由于每个entry中保存的都是自己的len长度,在牺牲掉机制的内存使用后,免去了连锁更新,看起来有着极大的性能提升,但是在内存使用率上比ziplist逊色不少。
其中insert中有LP_BEFORE与LP_AFTER两种情况,insert在最开始就将LP_BEFORE转变为LP_AFTER。redis将listpack中的删除操作变为置空,那么删除与修改也被统一成一类LP_REPLACE,所以增删改整体被处理过后,都在lpinsert中实现了,也仅仅是判断是处理LP_REPLACE还是LP_AFTER。
lpfind:
unsigned char *lpFind(unsigned char *lp, unsigned char *p, unsigned char *s,
uint32_t slen, unsigned int skip) {
//与ziplist的find类似,因为lp也提供给hash使用,因此lp的find函数也引入了skip字段,帮助lp只遍历key而非value
int skipcnt = 0;
unsigned char vencoding = 0;
unsigned char *value;
int64_t ll, vll;
uint64_t entry_size = 123456789; /* initialized to avoid warning. */
uint32_t lp_bytes = lpBytes(lp);
assert(p);
while (p) {
if (skipcnt == 0) {
value = lpGetWithSize(p, &ll, NULL, &entry_size);
if (value) {
if (slen == ll && memcmp(value, s, slen) == 0) {
return p;
}
} else {
/* Find out if the searched field can be encoded. Note that
* we do it only the first time, once done vencoding is set
* to non-zero and vll is set to the integer value. */
if (vencoding == 0) {
/* If the entry can be encoded as integer we set it to
* 1, else set it to UCHAR_MAX, so that we don't retry
* again the next time. */
if (slen >= 32 || slen == 0 || !lpStringToInt64((const char*)s, slen, &vll)) {
vencoding = UCHAR_MAX;
} else {
vencoding = 1;
}
}
/* Compare current entry with specified entry, do it only
* if vencoding != UCHAR_MAX because if there is no encoding
* possible for the field it can't be a valid integer. */
if (vencoding != UCHAR_MAX && ll == vll) {
return p;
}
}
/* Reset skip count */
skipcnt = skip;
p += entry_size;
} else {
/* Skip entry */
skipcnt--;
/* Move to next entry, avoid use `lpNext` due to `ASSERT_INTEGRITY` in
* `lpNext` will call `lpBytes`, will cause performance degradation */
p = lpSkip(p);
}
assert(p >= lp + LP_HDR_SIZE && p < lp + lp_bytes);
if (p[0] == LP_EOF) break;
}
return NULL;
}
来看find函数的话,其实没什么好说的,从头到尾遍历的操作。
listpack总结
- 从listpack自身来讲,把增删改统一成新增与修改两种模式,统一在lpinsert函数中实现,为listpack中的特色,redis其他数据结构并没有用到。而listpack的查找,从设计上来说,只能遍历,目前也看不到更好的优化。
- 与ziplist做对比的话,牺牲了内存使用率,避免了连锁更新的情况。从代码复杂度上看,listpack相对ziplist简单很多,再把增删改统一做处理,从listpack的代码实现上看,极简且高效。
- 从5中率先在streams中引入listpack,直到6后作为t_hash御用底层数据结构,redis应该是发现极致的内存使用远远不如提高redis的处理性能。也能看出来从redis08年出现到如今内存的普及与价格下降,各个平台qps的显著提高趋势。
- 从这里也可以猜到redis之后的优化趋势,将是淡化极致的内存使用率,向更快的方向发力。不过较为可惜的是,可能不会再出现堪称‘奇技淫巧’的类似ziplist,hyperloglog等复杂的代码了。

