码一个完整的prometheus exporter!
0 条评论相信经常使用prometheus的人对exporter不会陌生,而现有的exporter并不能完整的满足自己的需求,那就撸完一个完整的exporter!
首先,一个完整的exporter应该提供以下几类数据:
- 此exporter自身状态。
- 此exporter所监控目的组件的连接时间,是否可达(判断目的组件是否挂了)。
- 目的组件的详细监控数据。
以一个测试项目为例,完成一个的完整的exporter。
项目结构如下:
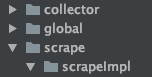
其中有四个文件夹,以下详细阐述每个文件夹里具体的功能
- global:主要完成一些公共使用类代码的封装以一些全局关键字的定义。
- scrape:scrape在prometheus里的功能是数据采集器,在这里主要是全局scrape的interface,具体实现在impl文件下完成。
- scrapeImpl:和上边scrape解释的一样,主要用来放置scrape的具体的实现类。每个实现类在写好后,注册到collector后暴露数据,在本文中放在main函数的[]里即可调用。
- collector:collector文件在本文这里类似数据注册器,所有的scrape需要被注册到collector里才能真正的被调用,将数据暴露出去。
- main: main函数单独拿出来说,功能为:装载collector,实现web接口,加载目的组件相关的数据(比如通过文件获取数据(blackboxexporter的yml文件),通过启动参数获取数据(mysqld_exporter的web.listen-address))。
话不多说,直接上代码,我们在本文里的exporter开发顺序为:在global里定义公共类和关键字-> 定义scrape接口->实现一个具体的测试scrapeImpl->完成collector->完成main函数
1.完成global部分
global下创建global.go
const (
// Exporter Namespace.
Namespace = "my_one_exporter"
)
Namespace将会经常被scrape和collector甚至main调用,因此放在了这里,也方便整体修改
func NewDesc(subsystem, name, help string) *prometheus.Desc {
return prometheus.NewDesc(
prometheus.BuildFQName(Namespace, subsystem, name),
help, nil, nil,
)
}
这里包装了下创建Desc的方法,之后每个scrapeImpl都会调用此方法,也放在global下了
完整的global.go代码如下:
package global
import "github.com/prometheus/client_golang/prometheus"
const (
// Exporter Namespace.
Namespace = "my_one_exporter"
)
func NewDesc(subsystem, name, help string) *prometheus.Desc {
return prometheus.NewDesc(
prometheus.BuildFQName(Namespace, subsystem, name),
help, nil, nil,
)
}
2.完成scrape部分
scrape文件夹下创建scraper.go
type Scraper interface {
// Name of the Scraper.
Name() string
// Help describes the role of the Scraper.
Help() string
// Scrape collects data from database connection and sends it over channel as prometheus metric.
Scrape(ctx context.Context, dc string, ch chan<- prometheus.Metric) error
}
其中name是每个scrapeImpl自己的名字,Help类似代码注释,反馈到最终效果是
# HELP my_one_exporter_myscraperonesubs_args my scraper one test args .
# TYPE my_one_exporter_myscraperonesubs_args counter
my_one_exporter_myscraperonesubs_args{args="argsone"} 0.01
里的#部分
里边Scrape的参数没什么要说的,主要是dc string这块,根据不同的监控目的组件这里需要换成不同的链接驱动,如果是mysqld_exporter的话需要换成
Scrape(ctx context.Context, db *sql.DB, ch chan<- prometheus.Metric) error
如果是redis_exporter的话换成
Scrape(ctx context.Context, c *redis.Conn, ch chan<- prometheus.Metric) error
只需注意在下边的Impl里切换成相对应的驱动就好,剩下的ctx和ch完全不用动照抄就行
scraper.go完整代码如下
package scrape
import (
"context"
"github.com/prometheus/client_golang/prometheus"
)
type Scraper interface {
// Name of the Scraper.
Name() string
// Help describes the role of the Scraper.
Help() string
// Scrape collects data from database connection and sends it over channel as prometheus metric.
Scrape(ctx context.Context, dc string, ch chan<- prometheus.Metric) error
}
3.完成scrapeImpl部分
scrapeImpl的话就要按照自己的具体业务更改了,这里只用一个例子来实现两种不同的注册效果
# TYPE my_one_exporter_myscraperonesubs_args counter
my_one_exporter_myscraperonesubs_args{args="argsone"} 0.01
# HELP my_one_exporter_myscraperonesubs_subsystemnameone Generic metric
# TYPE my_one_exporter_myscraperonesubs_subsystemnameone untyped
my_one_exporter_myscraperonesubs_subsystemnameone 0.01
在scrapeImpl下创建myscraperone.go
声明下必要关键字
const (
// Subsystem.
myscraperonesubs = "myscraperonesubs"
)
Subsystem的作用就类似于我这一个具体的scrapeImpl的名字(或者ID),向collector注册的时候告诉它我是谁(不可重名),在最终的数据层会被拼接成类似my_one_exporter_myscraperonesubs_subsystemnameone 0.01 这样的,其中my_one_exporter是我们最开始在global里定义的namespace,接下来的myscraperonesubs才是subsystem,后边的subsystemnameone我们在下边解释
再声明下Desc方法(Desc套路固定,cv即可)
var (
myscraperoneDesc = prometheus.NewDesc(
prometheus.BuildFQName(global.Namespace, myscraperonesubs, "args"),
"my scraper one test args .",
[]string{"args"}, nil,
)
)
这里需要详细看解释:
prometheus.BuildFQName里三个参数,global.Namespace是这个expoter的namespace,myscraperonesubs是我当前scrapeImpl的名字,后边的args是我具体一个指标的名称,在声明Desc的上一段里讲了my_one_exporter_myscraperonesubs_subsystemnameone的my_one_exporter和myscraperonesubs来源,那么最后一部分的subsystemnameone 就是这里写的args了,在这里我们写的是args,那么生成的指标就是my_one_exporter_myscraperonesubs_args 0.01
“my scraper one test args .” 这个是HELP说明,上边也讲了,这个会出现在最终的#***里,描述清楚这个指标是干嘛的即可
[]string{“args”} 这个需要强调下了,也关乎到下边代码的写法,需要仔细看下解释。在例子中我在字符数组里只写了args,那么最终的效果是my_one_exporter_myscraperonesubs_args{args=“argsone”} 0.01 里args="argsone"的args,也就是说,如果我写了[]string{“args1”,“args2”}那么最终就会形成my_one_exporter_myscraperonesubs_args{args1=“argsone1”,args2=“argsone2”} 0.01 这样的格式
代码继续开写:
func (MyScraperOne) Scrape(ctx context.Context, dc string, ch chan<- prometheus.Metric) error {
//get some from datacentor
//dc.dosomthing...
//may be return error,will stop this scrape's register
//return error
ch <- prometheus.MustNewConstMetric(
myscraperoneDesc, prometheus.CounterValue, 0.01, "argsone1",
)
ch <- prometheus.MustNewConstMetric(
global.NewDesc(myscraperonesubs, "subsystemnameone", "Generic metric"),
prometheus.UntypedValue,
0.01,
)
return nil
}
这里就得好好注意了
还记得上边在Scraper里讲的吗?dc string 这里可以替换成相对应的链接驱动,根据Scraper里的写法替换成一样的即可。
方法里前四行注释替换成你相对应的具体代码逻辑,如果是监控mysql,那就用db做具体的数据库curd操作,假如发生异常直接返回error退出此方法就行
ch <- prometheus.MustNewConstMetric(
myscraperoneDesc, prometheus.CounterValue, 0.01, "argsone1",
)
这句需要注意下,因为我在myscraperoneDesc里写的是[]string{“args”},只有一个label,所以我在注入数据的时候只写"argsone1"一个就行,假如你的myscraperoneDesc里写的是[]string{“args1”,“args2”},那么就得在这里写对应数量的value了"argsone1",“argsone2”,,这个写法会得到my_one_exporter_myscraperonesubs_args{args1=“argsone1”,args2=“argsone2”} 0.01
到此第一个scrapeImpl就全部写完了,众所周知metric的数据类型有四种,Counter,Gauge,Histogram,Counter,替换MustNewConstMetric成相对应的实现方法就好
myscraperone.go完整代码如下
package scrapeImpl
import (
"context"
"github.com/prometheus/client_golang/prometheus"
"test_exporter/global"
)
const (
// Subsystem.
myscraperonesubs = "myscraperonesubs"
)
var (
myscraperoneDesc = prometheus.NewDesc(
prometheus.BuildFQName(global.Namespace, myscraperonesubs, "args"),
"my scraper one test args .",
[]string{"args"}, nil,
)
)
type MyScraperOne struct{}
// Name of the Scraper. Should be unique.
func (MyScraperOne) Name() string {
return myscraperonesubs
}
// Help describes the role of the Scraper.
func (MyScraperOne) Help() string {
return "my scraper one"
}
func (MyScraperOne) Scrape(ctx context.Context, dc string, ch chan<- prometheus.Metric) error {
//get some from datacentor
//dc.dosomthing...
//may be return error,will stop this scrape's register
//return error
ch <- prometheus.MustNewConstMetric(
myscraperoneDesc, prometheus.CounterValue, 0.01, "argsone1",
)
ch <- prometheus.MustNewConstMetric(
global.NewDesc(myscraperonesubs, "subsystemnameone", "Generic metric"),
prometheus.UntypedValue,
0.01,
)
return nil
}
4.完成collector部分
collector相对来说就复杂一点了,我这里做三个功能
将写好的一个个scrapeImpl接管过来
记录监控目的组件是否可达
记录下每个scrapeImpl的执行时间(一般不做都行看个人喜好)
代码开始
const (
// Subsystem(s).
exporter = "exporter"
)
var (
scrapeDurationDesc = prometheus.NewDesc(
prometheus.BuildFQName(global.Namespace, exporter, "collector_duration_seconds"),
"Collector time duration.",
[]string{"collector"}, nil,
)
)
这里和scrapeImpl一样,不做过多解释了
type Metrics struct {
ExporterUp prometheus.Gauge
}
func NewMetrics() Metrics{
return Metrics{
ExporterUp: prometheus.NewGauge(prometheus.GaugeOpts{
Namespace: global.Namespace,
Name: "up",
Help: "Whether the datacenter is up.",
}),
}
}
这两个定义主要用来生成形如mysql_up,memcached_up,redis_up的metrics,也不用过多解释了
type Exporter struct {
ctx context.Context
dsn string
scrapers []scrape.Scraper
metrics Metrics
}
func New(ctx context.Context, dsn string, metrics Metrics, scrapers []scrape.Scraper) *Exporter {
return &Exporter{
ctx: ctx,
dsn: dsn,
scrapers: scrapers,
metrics: metrics,
}
}
这里的Exporter就是数据回收了,可以认为就是真正的Collector,New方法是给main函数调用的,无需考虑其他组件。说明下里边四个参数各自的作用:
ctx是http请求那里传过来的,需要使用ctx将本exporter抓取到的所有数据返回到response里,必带
dsn是exporter刚启动时从配置文件或者启动参数拿来的数据,用这个获取链接,比如dsn里是数据库的账号密码ip端口,通过这个建立连接,然后将具体链接传给一个个的Impl(毕竟大部分的prometheus采集周期都是15s,每个数据采集器(scrapeImpl)都重新开个链接没必要),dsn可以是结构体,看个人构造方便修改即可
scrapers们就是一个个的数据采集器(scrapeImpl)了,由于本身New方法是给main函数用的,所以一个完整的流程是:所有的scrapeImpl写好后先在main里声明到数组里,main函数调用collector的New时告诉collector有哪些scrapeImpl需要采集数据。至此完成了exporter的核心功能
metrics其实就是完成这个exporter自身的数据采集工作,也就是collector里的scrapeImpl,写在这里其实就是告诉collector也得采集exporter自己的数据。如果不想采集自身的话那就在main传一个空
func (e *Exporter) scrape(ctx context.Context, ch chan<- prometheus.Metric) {
ch <- prometheus.MustNewConstMetric(scrapeDurationDesc, prometheus.GaugeValue, 0.01, "version")
e.metrics.ExporterUp.Set(1)
var wg sync.WaitGroup
defer wg.Wait()
for _, scraper := range e.scrapers {
wg.Add(1)
go func(scraper scrape.Scraper) {
defer wg.Done()
label := "collect." + scraper.Name()
scrapeTime := time.Now()
if err := scraper.Scrape(ctx, "dc", ch); err != nil {
log.Println(err)
}
ch <- prometheus.MustNewConstMetric(scrapeDurationDesc, prometheus.GaugeValue, time.Since(scrapeTime).Seconds(), label)
}(scraper)
}
}
scrape方法就是灵魂的灵魂了,在这里开始启动所有传过来的scrapeImpl,并且记录下每个scrapeImpl的所用时长,这个写法是从mysqld_exprter那里照搬过来的,照抄就好
其中我直接设置ExporterUp为1了。具体到个人的up设置就根据e.dsn真正的去连接目的组件看是否真的可达。
func (e *Exporter) Describe(ch chan<- *prometheus.Desc) {
ch <- e.metrics.ExporterUp.Desc()
}
func (e *Exporter) Collect(ch chan<- prometheus.Metric) {
e.scrape(e.ctx, ch)
ch <- e.metrics.ExporterUp
}
这里不用更改
完整的exporter.go代码如下
package collector
import (
"context"
"github.com/prometheus/client_golang/prometheus"
"log"
"sync"
"test_exporter/global"
"test_exporter/scrape"
"time"
)
const (
// Subsystem(s).
exporter = "exporter"
)
var (
scrapeDurationDesc = prometheus.NewDesc(
prometheus.BuildFQName(global.Namespace, exporter, "collector_duration_seconds"),
"Collector time duration.",
[]string{"collector"}, nil,
)
)
type Metrics struct {
ExporterUp prometheus.Gauge
}
func NewMetrics() Metrics{
return Metrics{
ExporterUp: prometheus.NewGauge(prometheus.GaugeOpts{
Namespace: global.Namespace,
Name: "up",
Help: "Whether the datacenter is up.",
}),
}
}
type Exporter struct {
ctx context.Context
dsn string
scrapers []scrape.Scraper
metrics Metrics
}
func New(ctx context.Context, dsn string, metrics Metrics, scrapers []scrape.Scraper) *Exporter {
return &Exporter{
ctx: ctx,
dsn: dsn,
scrapers: scrapers,
metrics: metrics,
}
}
func (e *Exporter) Describe(ch chan<- *prometheus.Desc) {
ch <- e.metrics.ExporterUp.Desc()
}
func (e *Exporter) Collect(ch chan<- prometheus.Metric) {
e.scrape(e.ctx, ch)
ch <- e.metrics.ExporterUp
}
func (e *Exporter) scrape(ctx context.Context, ch chan<- prometheus.Metric) {
ch <- prometheus.MustNewConstMetric(scrapeDurationDesc, prometheus.GaugeValue, 0.01, "version")
e.metrics.ExporterUp.Set(1)
var wg sync.WaitGroup
defer wg.Wait()
for _, scraper := range e.scrapers {
wg.Add(1)
go func(scraper scrape.Scraper) {
defer wg.Done()
label := "collect." + scraper.Name()
scrapeTime := time.Now()
if err := scraper.Scrape(ctx, "dc", ch); err != nil {
log.Println(err)
}
ch <- prometheus.MustNewConstMetric(scrapeDurationDesc, prometheus.GaugeValue, time.Since(scrapeTime).Seconds(), label)
}(scraper)
}
}
5.完成main部分 完工!
func init() {
prometheus.MustRegister(version.NewCollector(global.Namespace+"_exporter"))
}
照搬就行。注册使用的
func newHandler(metrics collector.Metrics, scrapers []scrape.Scraper) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
mydsn := "ip:pord?username&password/url"
ctx := r.Context()
registry := prometheus.NewRegistry()
registry.MustRegister(collector.New(ctx, mydsn, metrics, scrapers))
gatherers := prometheus.Gatherers{
prometheus.DefaultGatherer,
registry,
}
h := promhttp.HandlerFor(gatherers, promhttp.HandlerOpts{})
h.ServeHTTP(w, r)
}
}
这里就比较灵活了,可以根据url传过来的参数拿到ip pord构造连接 比如r.URL.Query().Get(“ip”),但是数据库相关的账号密码会有安全问题。可以集成下告诉exporter去哪里取,这种方式的好处是一个exporter可以完美的复用多个节点(比如redis修改下这里的话一个exporter可以为一套cluster服务,无需一对一这么复杂) 也可以按照标准写法根据启动flag从启动参数或者打开文件获取相对应需要的数据,拼装好dsn后传给cllector即可
func main() {
enabledScrapers := []scrape.Scraper{scrapeImpl.MyScraperOne{}}
handlerFunc := newHandler(collector.NewMetrics(), enabledScrapers)
http.Handle("/metrics", promhttp.InstrumentMetricHandler(prometheus.DefaultRegisterer, handlerFunc))
srv := &http.Server{Addr: ":8000"}
web.ListenAndServe(srv, "", promlog.New(&promlog.Config{}))
}
这里可以把[]scrape.Scraper{scrapeImpl.MyScraperOne{}}单独拿出来声明,每实现好一个scrapeimpl后在这里加一下就可以直接生效了。
main.go的完整代码如下
package main
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"github.com/prometheus/common/promlog"
"github.com/prometheus/common/version"
"github.com/prometheus/exporter-toolkit/web"
"net/http"
"test_exporter/collector"
"test_exporter/global"
"test_exporter/scrape"
"test_exporter/scrape/scrapeImpl"
)
func init() {
prometheus.MustRegister(version.NewCollector(global.Namespace+"_exporter"))
}
func main() {
enabledScrapers := []scrape.Scraper{scrapeImpl.MyScraperOne{}}
handlerFunc := newHandler(collector.NewMetrics(), enabledScrapers)
http.Handle("/metrics", promhttp.InstrumentMetricHandler(prometheus.DefaultRegisterer, handlerFunc))
srv := &http.Server{Addr: ":8000"}
web.ListenAndServe(srv, "", promlog.New(&promlog.Config{}))
}
func newHandler(metrics collector.Metrics, scrapers []scrape.Scraper) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
mydsn := "ip:pord?username&password/url"
ctx := r.Context()
registry := prometheus.NewRegistry()
registry.MustRegister(collector.New(ctx, mydsn, metrics, scrapers))
gatherers := prometheus.Gatherers{
prometheus.DefaultGatherer,
registry,
}
h := promhttp.HandlerFor(gatherers, promhttp.HandlerOpts{})
h.ServeHTTP(w, r)
}
}

